本文以python为工具,对于豆瓣电影做了一定的可视化分析
具体的代码以及返回结果附在文末
数据规模
为了使得数据有代表性,本次分析共选取了从1902-2016共114年间的共一万五千多条数据。
电影评分总体趋势
本文对每一年豆瓣的电影的评分求了平均值,并且取了最近三十年的数据画了一个趋势图: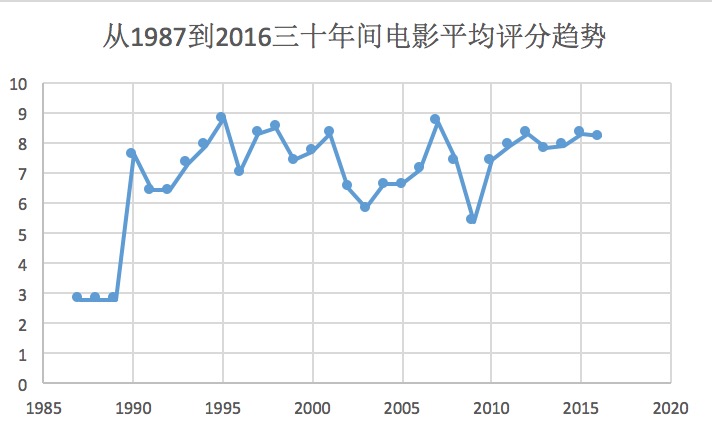
从图中我们可以看出,剔除极端值以后,近三十年来,电影事业总体发展较为平稳,偶有波动,平均电影分数稳定在7-8之间,这是一个比较高的水准。
电影类型介绍
本文对15000多部电影进行了归类,结果如下饼图:
(为方便统计,将总量小于20的电影归类于其他)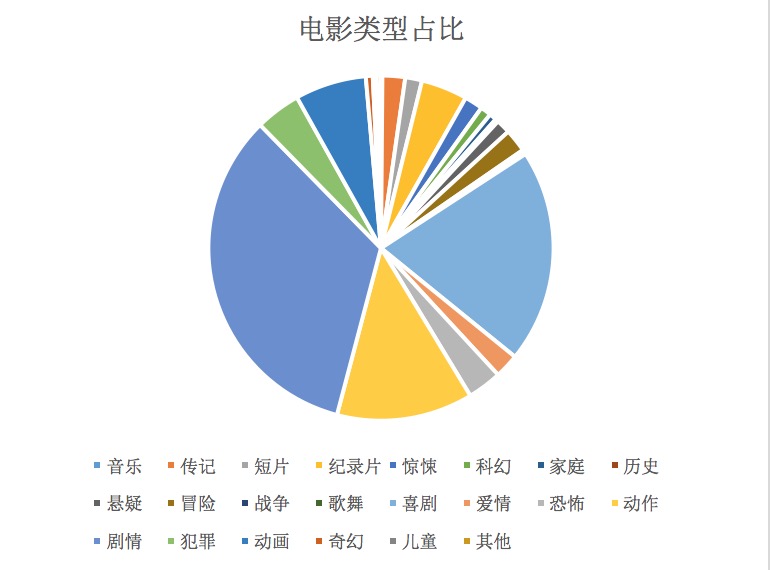
可以看出目前电影市场上有着各种类型的电影片子,其中最多的是剧情片,其次是喜剧片,动作、记录、犯罪等。
烂片、好片的比例
定义豆瓣电影评分大于9分的算好电影,小于5分的算坏电影
在统计的片子里面大约有5.73%的电影评分小于5分
大约有304部片子评分大于9分,占比约0.02%
说明电影行业发展参差不齐,出现了一些为了票房而滥竽充数之作,也侧面说明了观众对于电影评分的标准比较严格
评分最高、最低的电影
根据结果,评分最高的电影是:神秘博士:DT的视频日志:最后的日子,9.7分,属于纪录片
评分最低的电影是:嫁给大山的女人,2.1分,属于剧情片
评论最多的电影
根据结果,评论最多的电影同评分最高的电影,是:神秘博士:DT的视频日志:最后的日子
代码
|
|
返回结果:
min final:1902
max final:2016
year period:114
平均评分:
{1902: 6.2, 1903: 6.2, 1904: 5.0, 1905: 7.6, 1906: 6.7, 1907: 7.5, 1908: 6.3, 1911: 7.2, 1912: 6.2, 1914: 7.4, 1915: 7.8, 1916: 6.4, 1918: 7.9, 1919: 6.7, 1920: 7.0, 1921: 6.4, 1922: 8.0, 1923: 8.2, 1924: 7.6, 1925: 9.0, 1926: 8.3, 1927: 6.9, 1928: 7.5, 1929: 8.2, 1930: 7.0, 1931: 8.2, 1932: 7.9, 1933: 7.7, 1934: 5.3, 1935: 9.1, 1936: 7.4, 1937: 7.0, 1938: 8.0, 1939: 7.9, 1940: 7.9, 1941: 6.3, 1942: 6.6, 1943: 3.8, 1944: 8.0, 1945: 7.9, 1946: 6.8, 1947: 8.8, 1948: 7.6, 1949: 8.1, 1950: 7.8, 1951: 7.7, 1952: 7.5, 1953: 6.7, 1954: 7.7, 1955: 8.2, 1956: 6.8, 1957: 7.4, 1958: 8.7, 1959: 7.4, 1960: 6.7, 1961: 8.6, 1962: 6.9, 1963: 6.8, 1964: 5.4, 1965: 8.1, 1966: 7.8, 1967: 6.4, 1968: 8.7, 1969: 6.4, 1970: 4.9, 1971: 6.7, 1972: 5.7, 1973: 6.7, 1974: 8.0, 1975: 8.3, 1976: 7.6, 1977: 7.1, 1978: 7.1, 1979: 7.0, 1980: 7.5, 1981: 6.4, 1982: 6.4, 1983: 6.8, 1984: 6.2, 1985: 7.7, 1986: 6.1, 1987: 2.8, 1988: 2.8, 1989: 2.8, 1990: 7.6, 1991: 6.4, 1992: 6.4, 1993: 7.3, 1994: 7.9, 1995: 8.8, 1996: 7.0, 1997: 8.3, 1998: 8.5, 1999: 7.4, 2000: 7.7, 2001: 8.3, 2002: 6.5, 2003: 5.8, 2004: 6.6, 2005: 6.6, 2006: 7.1, 2007: 8.7, 2008: 7.4, 2009: 5.4, 2010: 7.4, 2011: 7.9, 2012: 8.3, 2013: 7.8, 2014: 7.9, 2015: 8.3, 2016: 8.2}
bad movies:5.73028586312%
num of each type:
音乐:21 同性:13 传记:327 短片:241 黑色电影:4 运动:7 纪录片:667 西部:16 惊悚:264 科幻:156 家庭:103 历史:44 武侠:4 悬疑:205 Adult:1 冒险:333 战争:38 歌舞:30 喜剧:3076 古装:3 情色:11 爱情:350 恐怖:493 动作:1961 剧情:5150 犯罪:653 动画:1026 奇幻:100 荒诞:1 灾难:1 儿童:57
num of movies whose score >= 9: 304
maxscore film :
IMDB: 5761 title:神秘博士:DT的视频日志:最后的日子 David Tennant‘s Video Diary - The Final Days type:纪录片
minscore film : IMDB: 487 title:嫁给大山的女人 type:剧情
movie with the most comment people film :
IMDB: 5761 title:神秘博士:DT的视频日志:最后的日子 David Tennant’s Video Diary - The Final Days type:纪录片