先导入需要的库
分析链家杭州二手房的网页信息:
有一百页的信息并无反爬虫限制,可以直接爬取。本次就是爬取这一百页。使用request库
|
|
其中直接快速获得元素xpath的小技巧:
在浏览器页面中选中元素,比如房子价格,右键检查,然后右键,copy to xpath。注意,如想选中一系列的价格,需要看多个房子的价格,并且找到规律。
比如:链家二手房中,第30个房子价格xpath:
|
|
最后的结果: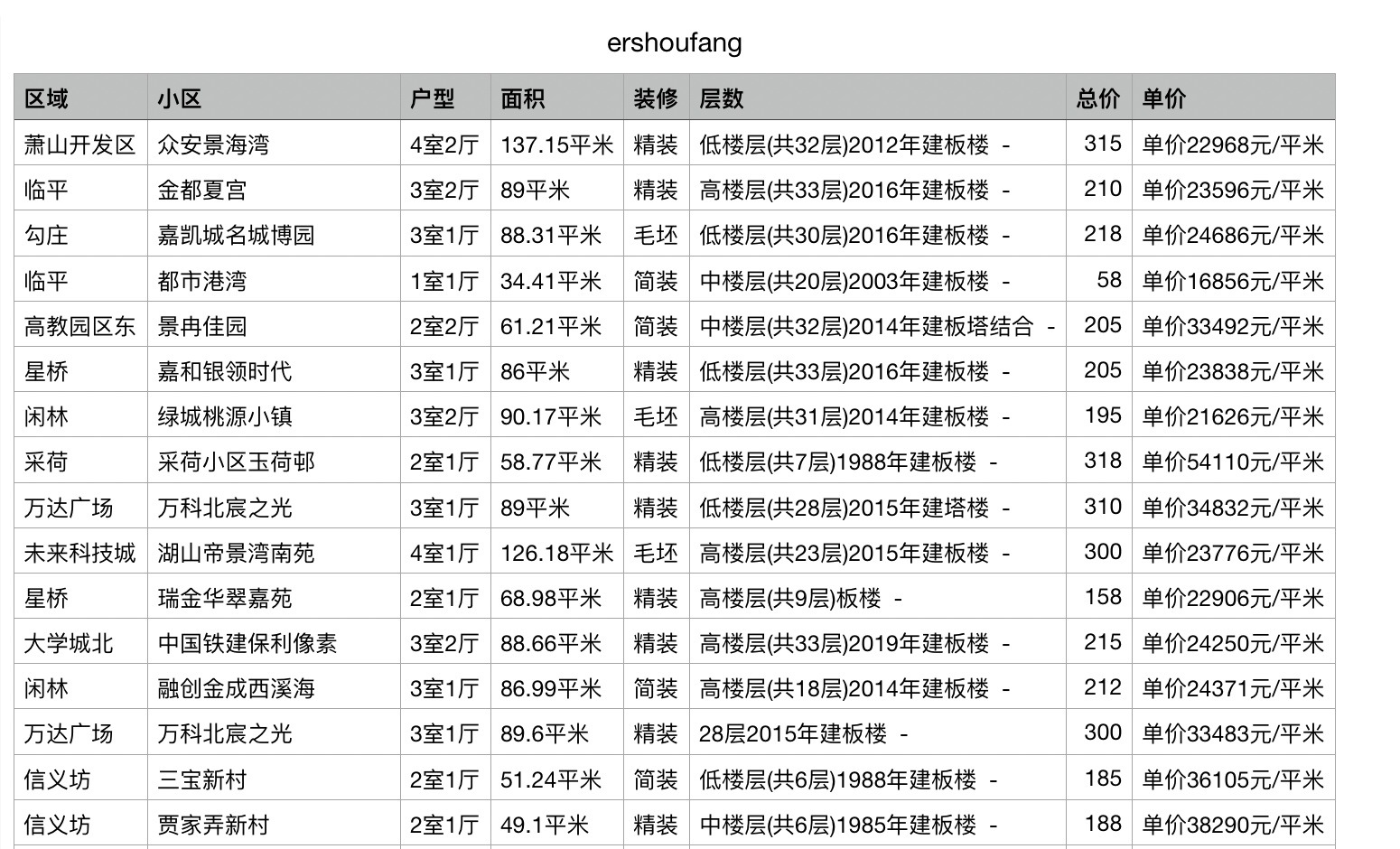
先导入需要的库
分析链家杭州二手房的网页信息:
有一百页的信息并无反爬虫限制,可以直接爬取。本次就是爬取这一百页。使用request库
|
|
其中直接快速获得元素xpath的小技巧:
在浏览器页面中选中元素,比如房子价格,右键检查,然后右键,copy to xpath。注意,如想选中一系列的价格,需要看多个房子的价格,并且找到规律。
比如:链家二手房中,第30个房子价格xpath:
|
|
最后的结果: