我的第一个爬虫项目
学习完python基本语法和基本静态网页爬虫之后深感自己需要拿点东西来练手,于是先找到了比较容易的豆瓣入手,最后导出成csv。朋友们可以根据豆瓣电影top250看起来啦。
主要使用的是request库和beautifulsoup去解析。中间在正则表达式上纠结了很久,网上搜了现成的但是怎么弄都不太对,后来发现是搞错了^这个符号。(敲重点:目前能在谷歌中找到的关于1-10位数字的匹配的正则表达式都不对)
代码:
|
|
最后的csv截取: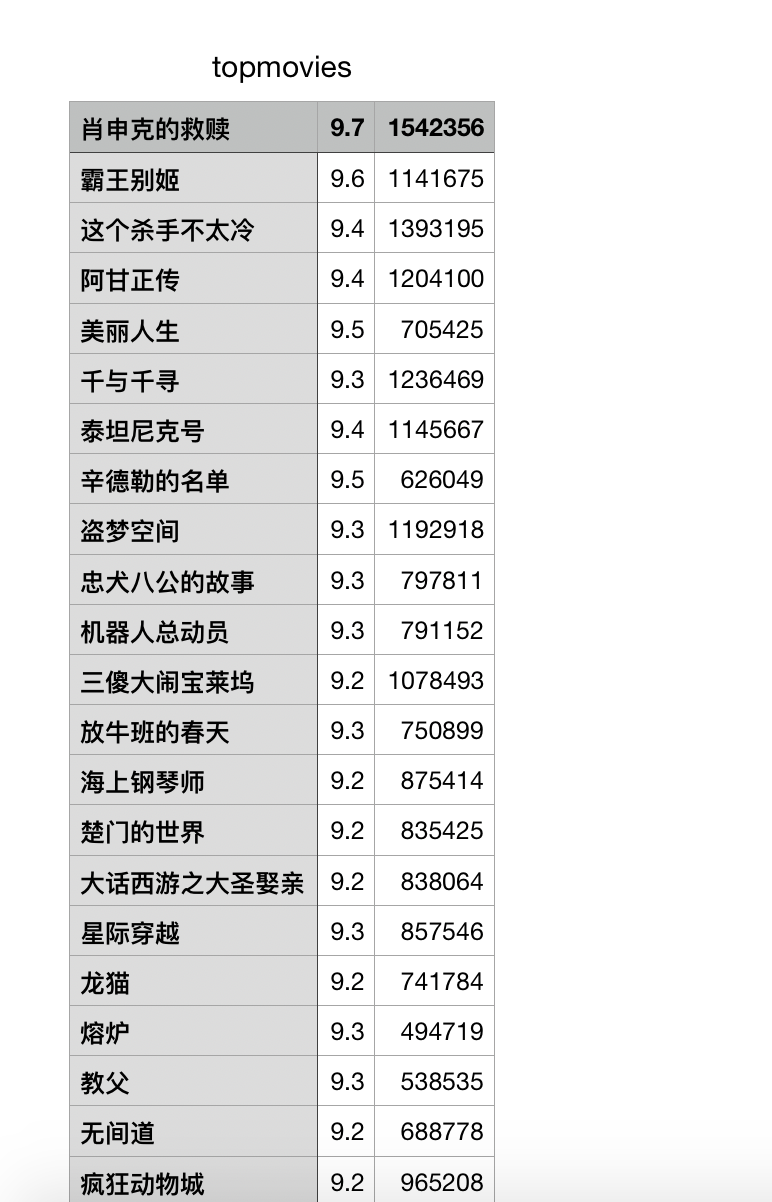
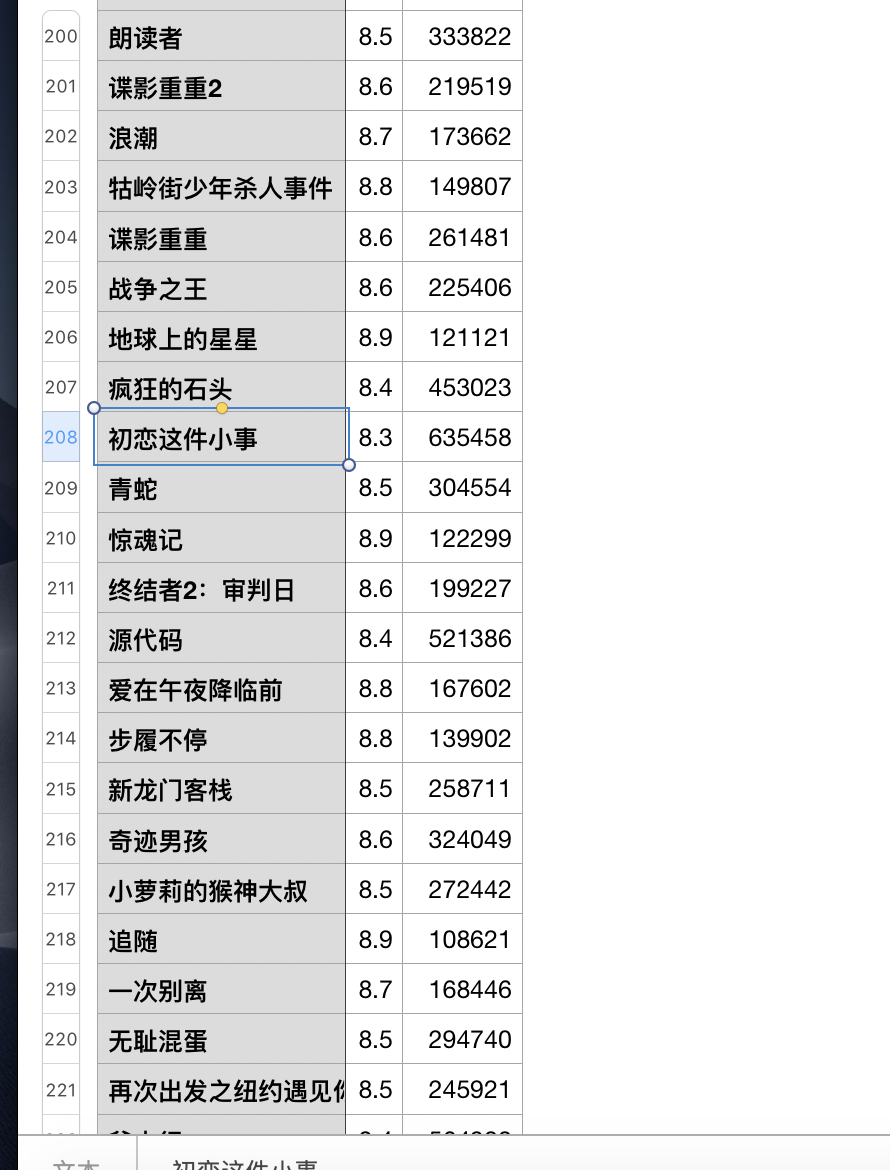
看起来top10的电影我只看了6/7部啊。
喜欢的初恋这件小事也上榜了哈哈